Models
Hindsight uses several machine learning models for different tasks.
Overview
- LLM — Fact extraction, reasoning, and generation. Provider-specific, fully configurable.
- Embedding — Vector representations for semantic search. Default:
BAAI/bge-small-en-v1.5. - Cross-Encoder — Reranking search results. Default:
cross-encoder/ms-marco-MiniLM-L-6-v2.
Embedding and cross-encoder models are downloaded automatically from HuggingFace on first run.
LLM
Used for fact extraction, entity resolution, mental model consolidation, and answer synthesis.
Supported providers:
Also supports any OpenAI-compatible API (e.g., Azure OpenAI, Together AI, Fireworks) and 100+ providers via LiteLLM (e.g., AWS Bedrock, Azure OpenAI, Together AI).
Hindsight works with any provider that exposes an OpenAI-compatible API (e.g., Azure OpenAI). Simply set HINDSIGHT_API_LLM_PROVIDER=openai and configure HINDSIGHT_API_LLM_BASE_URL to point to your provider's endpoint.
See Configuration for setup examples.
Set HINDSIGHT_API_LLM_PROVIDER=bedrock to use AWS Bedrock models directly. Model names use Bedrock model IDs (e.g., us.amazon.nova-2-lite-v1:0). No API key is required — authentication uses AWS credentials (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_REGION_NAME) or IAM roles. For 50% cost savings on throughput, set HINDSIGHT_API_LLM_BEDROCK_SERVICE_TIER=flex (see Configuration).
See Configuration for setup examples.
Set HINDSIGHT_API_LLM_PROVIDER=llamacpp to run a built-in llama.cpp server with no external dependencies. A Gemma 4 E2B GGUF model (~3.5 GB) is auto-downloaded on first run. Requires the local-llm extra: pip install 'hindsight-api-slim[local-llm]'.
The published Docker image does not bundle llama-cpp-python (to keep the image small). For a runnable Docker setup that adds it on top, see docker/docker-compose/local-llm/.
See Configuration for all options.
Set HINDSIGHT_API_LLM_PROVIDER=litellm to use any model supported by LiteLLM, including Azure OpenAI, Together AI, Fireworks AI, and many more. Model names use LiteLLM's provider prefix format (e.g., azure/gpt-4o).
See Configuration for setup examples.
Set HINDSIGHT_API_LLM_PROVIDER=litellmrouter to run the default LLM through LiteLLM's Router — ordered fallback across deployments, load-balanced same-tier routing, weighted picks, per-deployment rpm/tpm limits, and cooldowns are all available via the Router config. Hindsight passes the JSON config through verbatim.
See Configuration for setup.
Provider Capabilities
Beyond basic generation, some providers support optional features that lower cost or latency. Hindsight uses each feature automatically when the configured provider supports it.
| Provider | Batch API | Explicit prompt caching |
|---|---|---|
OpenAI (openai) | ✅ | — |
Anthropic (anthropic) | — | — |
Google Gemini (gemini) | ✅ | ✅ |
Vertex AI (vertexai) | — | ✅ |
Groq (groq) | ✅ | — |
Ollama (ollama) | — | — |
Ollama Cloud (ollama-cloud) | — | — |
LM Studio (lmstudio) | — | — |
llama.cpp (llamacpp) | — | — |
MiniMax (minimax) | — | — |
DeepSeek (deepseek) | — | — |
z.ai (zai) | — | — |
opencode-go (opencode-go) | — | — |
Atlas Cloud (atlas) | — | — |
Volcano Engine (volcano) | — | — |
OpenRouter (openrouter) | — | — |
Requesty (requesty) | — | — |
OpenAI Codex (openai-codex) | — | — |
Claude Code (claude-code) | — | — |
AWS Bedrock (bedrock) | — | — |
Fireworks AI (fireworks) | ✅ | — |
Nous Portal (nous) | — | — |
LiteLLM (100+) (litellm) | — | — |
- Batch API — submits bulk retain extraction through the provider's asynchronous batch endpoint, typically at ~50% lower cost. Used automatically when available; otherwise calls run synchronously.
- Explicit prompt caching — reuses the large, fixed system prefix that retain (fact extraction), consolidation, and the reflect tool-loop send on every call, billing it at the provider's cached-input rate. On Gemini/Vertex this uses the
CachedContentAPI. On by default; disable withHINDSIGHT_API_LLM_PROMPT_CACHE_ENABLED=false. Hindsight structures these prompts so the cached prefix is bank-agnostic — one cache is shared across all banks rather than one per bank/mission, and creation soft-fails to an uncached call, so it never breaks a request.
A blank "Explicit prompt caching" cell does not mean a provider has no caching. OpenAI, for example, caches a stable leading prompt prefix automatically server-side, so it benefits with no configuration; Anthropic supports caching via cache_control breakpoints which can be wired up through the same provider hook. The column tracks only Hindsight's explicit get_or_create_cached_prefix hook, which Gemini/Vertex implement today.
Benchmarks
Not sure which model to use? The Model Leaderboard benchmarks models across accuracy, speed, cost, and reliability for retain, reflect, and observation consolidation so you can pick the right trade-off for your use case.
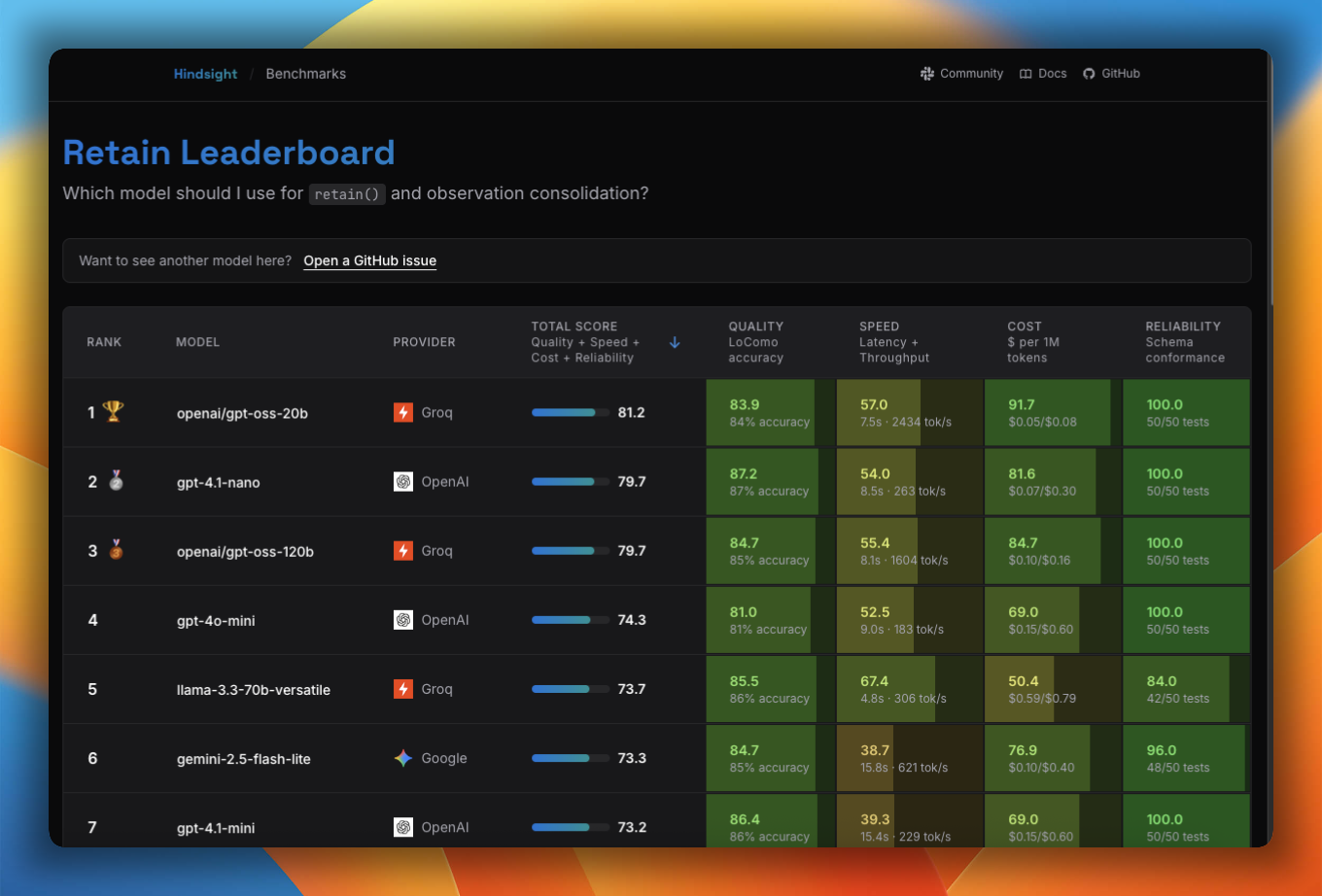
Tested Models
The following models have been tested and verified to work correctly with Hindsight:
| Provider | Model |
|---|---|
| OpenAI | gpt-5.2 |
| OpenAI | gpt-5 |
| OpenAI | gpt-5-mini |
| OpenAI | gpt-5-nano |
| OpenAI | gpt-4.1-mini |
| OpenAI | gpt-4.1-nano |
| OpenAI | gpt-4o-mini |
| Anthropic | claude-sonnet-4-20250514 |
| Anthropic | claude-3-5-sonnet-20241022 |
| Gemini | gemini-3.5-flash |
| Gemini | gemini-3.1-pro-preview |
| Gemini | gemini-3.1-flash-lite |
| Groq | openai/gpt-oss-120b |
| Groq | openai/gpt-oss-20b |
Provider Default Models
Each provider has a recommended default model that's used when HINDSIGHT_API_LLM_MODEL is not explicitly set. This makes configuration simpler - just specify the provider and get a sensible default:
| Provider | Default Model |
|---|---|
openai | gpt-4o-mini |
anthropic | claude-haiku-4-5 |
gemini | gemini-3.5-flash |
vertexai | google/gemini-3.1-flash-lite |
groq | openai/gpt-oss-120b |
ollama | gemma3:12b |
ollama-cloud | gemma3:12b |
lmstudio | local-model |
llamacpp | gemma-4-e2b-it (auto-downloaded GGUF) |
minimax | MiniMax-M3 |
deepseek | deepseek-v4-flash |
zai | glm-4.5-flash |
opencode-go | deepseek-v4-flash |
atlas | deepseek-ai/deepseek-v4-pro |
volcano | doubao-pro-32k |
openrouter | qwen/qwen3.5-9b |
requesty | openai/gpt-4o-mini |
openai-codex | gpt-5.4-mini |
claude-code | claude-sonnet-4-5-20250929 |
bedrock | us.amazon.nova-2-lite-v1:0 |
fireworks | accounts/fireworks/models/llama-v3p1-8b-instruct |
nous | deepseek/deepseek-v4-flash |
litellm | gpt-4o-mini |
Example: Setting just the provider uses its default model:
# Uses claude-haiku-4-5 automatically
export HINDSIGHT_API_LLM_PROVIDER=anthropic
export HINDSIGHT_API_LLM_API_KEY=sk-ant-xxxxxxxxxxxx
You can override the default by explicitly setting HINDSIGHT_API_LLM_MODEL:
# Override to use Sonnet instead
export HINDSIGHT_API_LLM_PROVIDER=anthropic
export HINDSIGHT_API_LLM_API_KEY=sk-ant-xxxxxxxxxxxx
export HINDSIGHT_API_LLM_MODEL=claude-sonnet-4-5-20250929
This also applies to per-operation overrides:
# Global: OpenAI gpt-4o-mini (default)
export HINDSIGHT_API_LLM_PROVIDER=openai
# Retain: Anthropic claude-haiku-4-5 (default)
export HINDSIGHT_API_RETAIN_LLM_PROVIDER=anthropic
Using Other Models
Other LLM models not listed above may work with Hindsight, but they must support at least 65,000 output tokens to ensure reliable fact extraction. If you need support for a specific model that doesn't meet this requirement, please open an issue to request an exception.
If your model only supports 32k or fewer output tokens (e.g., some older models), you can reduce the retain completion token limit:
# For models that support 32k output tokens
export HINDSIGHT_API_RETAIN_MAX_COMPLETION_TOKENS=32000
# For models that support 16k output tokens
export HINDSIGHT_API_RETAIN_MAX_COMPLETION_TOKENS=16000
Important: HINDSIGHT_API_RETAIN_MAX_COMPLETION_TOKENS must be greater than HINDSIGHT_API_RETAIN_CHUNK_SIZE (default: 3000). The system will validate this on startup and provide an error message if the configuration is invalid.
Groq's free tier only allows 8,000 tokens per minute — far below what Hindsight needs for a single retain call (~64k). Free-tier Groq models therefore can't be used with Hindsight; use a paid Groq tier or a different provider.
Configuration
# Groq (recommended)
export HINDSIGHT_API_LLM_PROVIDER=groq
export HINDSIGHT_API_LLM_API_KEY=gsk_xxxxxxxxxxxx
export HINDSIGHT_API_LLM_MODEL=openai/gpt-oss-20b
# OpenAI
export HINDSIGHT_API_LLM_PROVIDER=openai
export HINDSIGHT_API_LLM_API_KEY=sk-xxxxxxxxxxxx
export HINDSIGHT_API_LLM_MODEL=gpt-4o
# Gemini
export HINDSIGHT_API_LLM_PROVIDER=gemini
export HINDSIGHT_API_LLM_API_KEY=xxxxxxxxxxxx
export HINDSIGHT_API_LLM_MODEL=gemini-3.5-flash
# Anthropic
export HINDSIGHT_API_LLM_PROVIDER=anthropic
export HINDSIGHT_API_LLM_API_KEY=sk-ant-xxxxxxxxxxxx
export HINDSIGHT_API_LLM_MODEL=claude-sonnet-4-20250514
# Ollama (local)
export HINDSIGHT_API_LLM_PROVIDER=ollama
export HINDSIGHT_API_LLM_BASE_URL=http://localhost:11434/v1
export HINDSIGHT_API_LLM_MODEL=llama3
# Ollama Cloud (hosted Ollama endpoint, requires API key)
export HINDSIGHT_API_LLM_PROVIDER=ollama-cloud
export HINDSIGHT_API_LLM_API_KEY=your-ollama-cloud-api-key
export HINDSIGHT_API_LLM_MODEL=gemma3:12b
# LM Studio (local)
export HINDSIGHT_API_LLM_PROVIDER=lmstudio
export HINDSIGHT_API_LLM_BASE_URL=http://localhost:1234/v1
export HINDSIGHT_API_LLM_MODEL=your-local-model
# MiniMax (1M context window)
export HINDSIGHT_API_LLM_PROVIDER=minimax
export HINDSIGHT_API_LLM_API_KEY=your-minimax-api-key
export HINDSIGHT_API_LLM_MODEL=MiniMax-M3 # or MiniMax-M2.7 for the previous generation
# DeepSeek (https://api.deepseek.com)
export HINDSIGHT_API_LLM_PROVIDER=deepseek
export HINDSIGHT_API_LLM_API_KEY=sk-xxxxxxxxxxxx
export HINDSIGHT_API_LLM_MODEL=deepseek-v4-flash # or deepseek-v4-pro / deepseek-chat / deepseek-reasoner
# z.ai (Zhipu GLM series, OpenAI-compatible, https://z.ai)
export HINDSIGHT_API_LLM_PROVIDER=zai
export HINDSIGHT_API_LLM_API_KEY=your-zai-api-key
export HINDSIGHT_API_LLM_MODEL=glm-4.5-flash # or glm-4.5-air for the paid tier
# opencode-go (OpenAI-compatible)
export HINDSIGHT_API_LLM_PROVIDER=opencode-go
export HINDSIGHT_API_LLM_API_KEY=your-opencode-go-api-key
export HINDSIGHT_API_LLM_MODEL=deepseek-v4-flash
# Atlas Cloud (OpenAI-compatible, https://www.atlascloud.ai)
export HINDSIGHT_API_LLM_PROVIDER=atlas
export HINDSIGHT_API_LLM_API_KEY=your-atlascloud-api-key # base_url defaults to https://api.atlascloud.ai/v1
export HINDSIGHT_API_LLM_MODEL=deepseek-ai/deepseek-v4-pro # reasoning model; also Qwen / GLM / Kimi / MiniMax, etc.
# Nous Portal (OpenAI-compatible; no API key — uses your `hermes portal` login)
export HINDSIGHT_API_LLM_PROVIDER=nous
export HINDSIGHT_API_LLM_MODEL=deepseek/deepseek-v4-flash # any Nous-hosted slug
# No API key needed — reads a rotating JWT from ~/.hermes/auth.json (see "Nous Portal Setup" below)
# Vertex AI (Google Cloud)
export HINDSIGHT_API_LLM_PROVIDER=vertexai
export HINDSIGHT_API_LLM_MODEL=gemini-3.1-flash-lite
export HINDSIGHT_API_LLM_VERTEXAI_PROJECT_ID=your-gcp-project-id
# Optional: region (default: us-central1)
# export HINDSIGHT_API_LLM_VERTEXAI_REGION=us-central1
# Optional: service account key (otherwise uses ADC)
# export HINDSIGHT_API_LLM_VERTEXAI_SERVICE_ACCOUNT_KEY=/path/to/key.json
Note: The LLM is the primary bottleneck for retain operations. See Performance for optimization strategies.
OpenAI Codex Setup (ChatGPT Plus/Pro)
Use your ChatGPT Plus or Pro subscription for Hindsight without separate OpenAI Platform API costs.
Prerequisites:
- Active ChatGPT Plus or Pro subscription
- Node.js/npm installed (for Codex CLI)
Setup Steps:
-
Install Codex CLI:
npm install -g @openai/codex -
Login with ChatGPT credentials:
codex auth loginThis opens a browser window to authenticate with your ChatGPT account and saves OAuth tokens to
~/.codex/auth.json. -
Verify authentication:
ls ~/.codex/auth.json # Should show the auth file exists -
Configure Hindsight:
export HINDSIGHT_API_LLM_PROVIDER=openai-codex
# export HINDSIGHT_API_LLM_MODEL=gpt-5.6-luna # defaults to gpt-5.4-mini
# No API key needed - reads from ~/.codex/auth.json automatically -
Start Hindsight:
hindsight-api
You can use any model supported by OpenAI Codex CLI
Important Notes:
- OAuth tokens are stored in
~/.codex/auth.json - Tokens refresh automatically when needed
- Usage is billed to your ChatGPT subscription (not separate API costs)
- For personal development use only (see ChatGPT Terms of Service)
Isolating Codex auth for long-running services
By default Hindsight reads Codex credentials from ~/.codex/auth.json — the
same file the @openai/codex CLI, editor plugins, and other agent runtimes use.
This is convenient for local development but can cause a subtle failure mode when
Hindsight runs as a long-lived service (systemd unit, container, background
daemon) alongside another Codex process:
- Codex refresh tokens are single-use and rotate on refresh.
- If another process refreshes the shared token, Hindsight's long-running process is left holding a stale refresh token.
- Recall and
/healthkeep working (the database and API are fine), but/reflectfails with an error such as:Codex refresh_token is permanently invalid (error.code=refresh_token_reused).
Run 'codex auth login' to re-authenticate.
To avoid this, give the Hindsight service its own dedicated Codex auth home
via the CODEX_HOME environment variable. Hindsight honors CODEX_HOME exactly
like the @openai/codex CLI: when set, it reads $CODEX_HOME/auth.json instead
of ~/.codex/auth.json.
# Dedicated credentials directory for the Hindsight service
export CODEX_HOME=/var/lib/hindsight/codex
# One-time login into that isolated home (opens a browser / device-code flow)
codex auth login # writes $CODEX_HOME/auth.json
export HINDSIGHT_API_LLM_PROVIDER=openai-codex
hindsight-api
For a systemd unit, set it in the service definition so it never shares auth with an interactive Codex session:
[Service]
Environment=CODEX_HOME=/var/lib/hindsight/codex
After a fresh login into the dedicated home and restarting only the Hindsight
service, /reflect uses its own token that other Codex processes will not
rotate out from under it.
CODEX_HOME is also honored by the openai-codex embeddings provider.
Nous Portal Setup (Hermes)
Use your Nous Portal subscription for Hindsight via the Hermes CLI login — no static API key required.
Prerequisites:
- A Nous Portal account
- The Hermes CLI installed
Setup Steps:
-
Log in to Nous Portal:
hermes portalThis opens a browser to authenticate with Nous Portal and saves OAuth credentials to
~/.hermes/auth.json. -
Verify authentication:
hermes portal status # should show "Auth: ✓ logged in" -
Configure Hindsight:
export HINDSIGHT_API_LLM_PROVIDER=nous
# export HINDSIGHT_API_LLM_MODEL=deepseek/deepseek-v4-flash # defaults to deepseek/deepseek-v4-flash
# No API key needed — reads from ~/.hermes/auth.json automatically -
Start Hindsight:
hindsight-api
You can use any model hosted on the Nous Portal inference API.
Important Notes:
- Credentials are read from
~/.hermes/auth.json(the same store the Hermes agent uses) — no static API key in Hindsight's config. - The short-lived inference JWT is refreshed automatically, before expiry and reactively on a 401.
- Refreshes coordinate with a running Hermes agent through the shared auth store, so the two never disrupt each other's session.
- Default base URL:
https://inference-api.nousresearch.com/v1(override withHINDSIGHT_API_LLM_BASE_URL).
Claude Code Setup (Claude Pro/Max)
Use your Claude Pro or Max subscription for Hindsight without separate Anthropic API costs.
This integration uses the Claude Agent SDK with your personal Claude Pro/Max subscription credentials. You must be logged into Claude Code on your own machine before using this provider.
Please be aware:
- Anthropic's Agent SDK documentation
states that third-party developers should not offer claude.ai login or rate limits for
their products. Hindsight does not perform any login on your behalf — it uses
credentials you've already authenticated via
claude auth login. - In January 2026, Anthropic enforced restrictions against third-party tools using Claude subscription OAuth tokens. Those restrictions targeted tools that spoofed the Claude Code client identity — Hindsight uses the official Claude Agent SDK instead.
- This provider is intended for local, personal development use only. Do not use it in production deployments or shared environments.
- Anthropic's terms may change. If you want guaranteed compliance, use the
anthropicprovider with an API key instead. - Usage counts against your Claude Pro/Max subscription limits.
For production or team use, we recommend using HINDSIGHT_API_LLM_PROVIDER=anthropic with
an API key from the Anthropic Console.
Prerequisites:
- Active Claude Pro or Max subscription
- Claude Code CLI installed
Setup Steps:
-
Install Claude Code CLI:
npm install -g @anthropics/claude-code
# Or via Homebrew
brew install anthropics/claude-code/claude-code -
Login with Claude credentials:
claude auth loginThis opens a browser window to authenticate with your Claude account. Authentication is automatically managed by the Claude Agent SDK.
-
Verify authentication:
claude --version
# Should show version without errors -
Configure Hindsight:
export HINDSIGHT_API_LLM_PROVIDER=claude-code
# No API key needed - uses claude auth login credentials -
Start Hindsight:
hindsight-api
You can use any model supported by Claude Code CLI.
Important Notes:
- Authentication handled by Claude Agent SDK (uses bundled CLI)
- Credentials managed securely by Claude Code
- Usage billed to your Claude subscription (not separate API costs)
- For personal development use only (see Claude Terms of Service)
Vertex AI Setup (Google Cloud)
Google Cloud's Vertex AI provides access to Gemini models via the native Google GenAI SDK.
Prerequisites:
- GCP project with Vertex AI API enabled
- IAM role
roles/aiplatform.userfor your credentials
Environment Variables:
| Variable | Description | Required |
|---|---|---|
HINDSIGHT_API_LLM_VERTEXAI_PROJECT_ID | Your GCP project ID | Yes |
HINDSIGHT_API_LLM_VERTEXAI_REGION | GCP region (e.g., us-central1) | No (default: us-central1) |
HINDSIGHT_API_LLM_VERTEXAI_SERVICE_ACCOUNT_KEY | Path to service account JSON key file | No (uses ADC if not set) |
Authentication Methods:
-
Application Default Credentials (ADC) - Recommended for development
# Setup ADC
gcloud auth application-default login
# Configure Hindsight
export HINDSIGHT_API_LLM_PROVIDER=vertexai
export HINDSIGHT_API_LLM_MODEL=gemini-3.1-flash-lite
export HINDSIGHT_API_LLM_VERTEXAI_PROJECT_ID=your-project-id -
Service Account Key - Recommended for production
# Create service account and download key
gcloud iam service-accounts create hindsight-api
gcloud projects add-iam-policy-binding your-project-id \
--member="serviceAccount:hindsight-api@your-project-id.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud iam service-accounts keys create key.json \
--iam-account=hindsight-api@your-project-id.iam.gserviceaccount.com
# Configure Hindsight
export HINDSIGHT_API_LLM_PROVIDER=vertexai
export HINDSIGHT_API_LLM_MODEL=gemini-3.1-flash-lite
export HINDSIGHT_API_LLM_VERTEXAI_PROJECT_ID=your-project-id
export HINDSIGHT_API_LLM_VERTEXAI_SERVICE_ACCOUNT_KEY=/path/to/key.json
Notes:
- Model names can optionally include the
google/prefix (e.g.,google/gemini-3.1-flash-lite) — it will be stripped automatically - The native SDK handles token refresh automatically
- Uses service account credentials if provided, otherwise falls back to ADC
Embedding Model
Converts text into dense vector representations for semantic similarity search.
Default: BAAI/bge-small-en-v1.5 (384 dimensions, ~130MB)
Supported Providers
| Provider | Description | Best For |
|---|---|---|
local | SentenceTransformers (default) | Development, low latency |
onnx | In-process ONNX Runtime embedder (no Ollama/TEI/API sidecar) | Lightweight local CPU, multilingual |
openai | OpenAI embeddings API | Production, high quality |
openai-codex | OpenAI embeddings via Codex OAuth (ChatGPT Plus/Pro, no API key) | Existing ChatGPT/Codex subscribers |
openrouter | OpenRouter embeddings (OpenAI-compatible gateway) | Multi-provider setups |
cohere | Cohere embeddings API | Production, multilingual |
google | Google embeddings (Gemini API or Vertex AI) | Production, multilingual, high quality |
tei | HuggingFace Text Embeddings Inference | Production, self-hosted |
zeroentropy | ZeroEntropy zembed-1 | Production, high quality retrieval |
litellm | LiteLLM proxy (unified gateway) | Multi-provider setups |
litellm-sdk | LiteLLM SDK (direct API, no proxy) | Multi-provider, simpler setup |
Local Models
| Model | Dimensions | Use Case |
|---|---|---|
BAAI/bge-small-en-v1.5 | 384 | Default, fast, good quality |
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | 384 | Multilingual (50+ languages) |
OpenAI Models
| Model | Dimensions | Use Case |
|---|---|---|
text-embedding-3-small | 1536 | Default OpenAI, cost-effective |
text-embedding-3-large | 3072 | Higher quality, more expensive |
text-embedding-ada-002 | 1536 | Legacy model |
Google Models
| Model | Dimensions | Use Case |
|---|---|---|
gemini-embedding-001 | 768 (configurable) | Default Google, general purpose |
gemini-embedding-2-preview | 768 (configurable) | Gemini Embedding 2 family; multimodal, one vector per input |
Google's gemini-embedding-001 supports configurable output dimensionality via truncation, google recommend using: 768, 1536, 3072, via HINDSIGHT_API_EMBEDDINGS_GEMINI_OUTPUT_DIMENSIONALITY. Default is 768.
The gemini-embedding-2 family, including gemini-embedding-2-preview, is supported on both the Gemini API and Vertex AI. These models aggregate multi-input requests, so Hindsight automatically embeds one input per call to keep per-fact vectors aligned.
Cohere Models
| Model | Dimensions | Use Case |
|---|---|---|
embed-english-v3.0 | 1024 | English text |
embed-multilingual-v3.0 | 1024 | 100+ languages |
ZeroEntropy Models
| Model | Dimensions | Use Case |
|---|---|---|
zembed-1 | 1280 default (2560/1280/640/320/160/80/40 configurable) | High quality asymmetric retrieval |
Hindsight sends retained memory text to ZeroEntropy as document inputs and recall/search text as query inputs. ZeroEntropy's API default is 2560 dimensions; Hindsight defaults to 1280 so pgvector HNSW works without changing the vector extension.
Hindsight automatically detects the embedding dimension at startup and adjusts the database schema. Once memories are stored, you cannot change dimensions without losing data.
Configuration Examples:
# Local provider (default)
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=local
export HINDSIGHT_API_EMBEDDINGS_LOCAL_MODEL=BAAI/bge-small-en-v1.5
# ONNX provider (in-process local CPU, no Ollama/TEI/API sidecar; pip install hindsight-api-slim[local-onnx])
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=onnx
export HINDSIGHT_API_EMBEDDINGS_ONNX_MODEL_ID=intfloat/multilingual-e5-small
export HINDSIGHT_API_EMBEDDINGS_ONNX_DIMENSIONS=384
# OpenAI
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=openai
export HINDSIGHT_API_EMBEDDINGS_OPENAI_API_KEY=sk-xxxxxxxxxxxx
export HINDSIGHT_API_EMBEDDINGS_OPENAI_MODEL=text-embedding-3-small
# Cohere
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=cohere
export HINDSIGHT_API_COHERE_API_KEY=your-api-key
export HINDSIGHT_API_EMBEDDINGS_COHERE_MODEL=embed-english-v3.0
# Google (API key auth)
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=google
export HINDSIGHT_API_EMBEDDINGS_GEMINI_API_KEY=xxxxxxxxxxxx
export HINDSIGHT_API_EMBEDDINGS_GEMINI_MODEL=gemini-embedding-001
# Google (Vertex AI auth - auto-detected when project ID is set)
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=google
export HINDSIGHT_API_EMBEDDINGS_GEMINI_MODEL=gemini-embedding-001
export HINDSIGHT_API_EMBEDDINGS_VERTEXAI_PROJECT_ID=your-gcp-project-id
# TEI (self-hosted)
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=tei
export HINDSIGHT_API_EMBEDDINGS_TEI_URL=http://localhost:8080
# ZeroEntropy
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=zeroentropy
export HINDSIGHT_API_EMBEDDINGS_ZEROENTROPY_API_KEY=your-api-key
export HINDSIGHT_API_EMBEDDINGS_ZEROENTROPY_MODEL=zembed-1
export HINDSIGHT_API_EMBEDDINGS_ZEROENTROPY_DIMENSIONS=1280
# LiteLLM proxy
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=litellm
export HINDSIGHT_API_LITELLM_API_BASE=http://localhost:4000
export HINDSIGHT_API_EMBEDDINGS_LITELLM_MODEL=text-embedding-3-small
# LiteLLM SDK (direct, no proxy)
export HINDSIGHT_API_EMBEDDINGS_PROVIDER=litellm-sdk
export HINDSIGHT_API_EMBEDDINGS_LITELLM_SDK_API_KEY=sk-xxxxxxxxxxxx
export HINDSIGHT_API_EMBEDDINGS_LITELLM_SDK_MODEL=openai/text-embedding-3-small
See Configuration for all options including Azure OpenAI and custom endpoints.
Cross-Encoder (Reranker)
Reranks initial search results to improve precision.
Default: cross-encoder/ms-marco-MiniLM-L-6-v2 (~85MB)
Supported Providers
| Provider | Description | Best For |
|---|---|---|
local | SentenceTransformers CrossEncoder (default) | Development, low latency |
cohere | Cohere rerank API | Production, high quality |
openrouter | OpenRouter rerank API (Cohere-compatible gateway) | Multi-provider setups |
zeroentropy | ZeroEntropy rerank API (zerank-2) | Production, state-of-the-art accuracy |
siliconflow | SiliconFlow rerank API (Cohere-compatible /rerank endpoint) | Users in China or anyone on SiliconFlow's platform |
alibaba | Alibaba Cloud DashScope rerank API (qwen3-rerank) | Users on Alibaba Cloud / DashScope |
google | Google Discovery Engine ranking API (REST + Google auth) | Production, GCP integration |
tei | HuggingFace Text Embeddings Inference | Production, self-hosted |
flashrank | FlashRank (lightweight, fast) | Resource-constrained environments |
litellm | LiteLLM proxy (unified gateway) | Multi-provider setups |
litellm-sdk | LiteLLM SDK (direct API, no proxy) | Multi-provider, simpler setup |
jina-mlx | Jina rerank v3 via Apple Silicon MLX (local, no API key) | Apple Silicon (M1+) local inference |
rrf | RRF-only (no neural reranking) | Testing, minimal resources |
Local Models
| Model | Use Case |
|---|---|
cross-encoder/ms-marco-MiniLM-L-6-v2 | Default, fast |
cross-encoder/ms-marco-MiniLM-L-12-v2 | Higher accuracy |
cross-encoder/mmarco-mMiniLMv2-L12-H384-v1 | Multilingual |
Cohere Models
| Model | Use Case |
|---|---|
rerank-english-v3.0 | English text |
rerank-multilingual-v3.0 | 100+ languages |
ZeroEntropy Models
| Model | Use Case |
|---|---|
zerank-2 | Flagship multilingual reranker (default) |
zerank-2-small | Faster, lighter variant |
SiliconFlow Models
SiliconFlow hosts a range of open-weight rerankers behind a Cohere-compatible /rerank endpoint:
| Model | Use Case |
|---|---|
BAAI/bge-reranker-v2-m3 | Multilingual, strong default |
Qwen/Qwen3-Reranker-8B | Larger, higher accuracy |
Alibaba Cloud Models
Alibaba Cloud DashScope exposes qwen3-rerank via a Cohere-compatible /reranks endpoint:
| Model | Use Case |
|---|---|
qwen3-rerank | 100+ languages, default |
LiteLLM Supported Providers
LiteLLM supports multiple reranking providers via the /rerank endpoint:
| Provider | Model Example |
|---|---|
| Cohere | cohere/rerank-english-v3.0 |
| Together AI | together_ai/... |
| Voyage AI | voyage/rerank-2 |
| Jina AI | jina_ai/... |
| AWS Bedrock | bedrock/... |
Configuration Examples:
# Local provider (default)
export HINDSIGHT_API_RERANKER_PROVIDER=local
export HINDSIGHT_API_RERANKER_LOCAL_MODEL=cross-encoder/ms-marco-MiniLM-L-6-v2
# Cohere
export HINDSIGHT_API_RERANKER_PROVIDER=cohere
export HINDSIGHT_API_COHERE_API_KEY=your-api-key
export HINDSIGHT_API_RERANKER_COHERE_MODEL=rerank-english-v3.0
# Cohere-compatible endpoint (Azure AI Foundry, Jina, Voyage, self-hosted BGE, ...)
# Setting COHERE_BASE_URL switches the provider off the Cohere SDK and onto a
# plain HTTP client that speaks the standard rerank wire format:
# POST {base_url} Authorization: Bearer <key>
# {"model","query","documents","return_documents":false}
# -> {"results":[{"index","relevance_score"}, ...]}
export HINDSIGHT_API_RERANKER_PROVIDER=cohere
export HINDSIGHT_API_RERANKER_COHERE_API_KEY=your-api-key
export HINDSIGHT_API_RERANKER_COHERE_MODEL=rerank-v3.5 # whatever model the endpoint serves
export HINDSIGHT_API_RERANKER_COHERE_BASE_URL=https://your-endpoint.example/rerank
# ZeroEntropy (state-of-the-art accuracy)
export HINDSIGHT_API_RERANKER_PROVIDER=zeroentropy
export HINDSIGHT_API_RERANKER_ZEROENTROPY_API_KEY=your-api-key
export HINDSIGHT_API_RERANKER_ZEROENTROPY_MODEL=zerank-2 # default, can omit
# SiliconFlow (Cohere-compatible /rerank endpoint)
export HINDSIGHT_API_RERANKER_PROVIDER=siliconflow
export HINDSIGHT_API_RERANKER_SILICONFLOW_API_KEY=your-api-key
export HINDSIGHT_API_RERANKER_SILICONFLOW_MODEL=BAAI/bge-reranker-v2-m3 # default, can omit
# Alibaba Cloud DashScope (qwen3-rerank)
export HINDSIGHT_API_RERANKER_PROVIDER=alibaba
export HINDSIGHT_API_RERANKER_ALIBABA_API_KEY=your-dashscope-api-key
export HINDSIGHT_API_RERANKER_ALIBABA_MODEL=qwen3-rerank # default, can omit
# TEI (self-hosted)
export HINDSIGHT_API_RERANKER_PROVIDER=tei
export HINDSIGHT_API_RERANKER_TEI_URL=http://localhost:8081
# FlashRank (lightweight)
export HINDSIGHT_API_RERANKER_PROVIDER=flashrank
# LiteLLM proxy
export HINDSIGHT_API_RERANKER_PROVIDER=litellm
export HINDSIGHT_API_LITELLM_API_BASE=http://localhost:4000
export HINDSIGHT_API_RERANKER_LITELLM_MODEL=cohere/rerank-english-v3.0
# RRF-only (no neural reranking)
export HINDSIGHT_API_RERANKER_PROVIDER=rrf
See Configuration for all options including Azure-hosted endpoints and batch settings.