What's new in Hindsight 0.8.0

Hindsight 0.8.0 is a major release focused on running memory at scale and seeing inside it. Banks can now move between instances with a built-in export/import, every LLM call behind retain, recall, and reflect is traced out of the box, consolidation is far more reliable thanks to built-in de-duplication that catches the LLM drift that used to leave duplicate observations behind, and provider prompt caching cuts the cost and latency of the LLM calls Hindsight makes on your behalf.
- Cross-Instance Bank Migration: Export a whole bank — or just its documents — and import it into another Hindsight instance, re-embedding locally with no LLM re-run.
- Operations & Observability: Full LLM request tracing on by default, resumable long-running operations, and clearer operational views in the Control Plane.
- Smarter Consolidation: Built-in de-duplication that fixes the LLM drift behind duplicate observations, on by default.
- Provider Prompt Caching: Prompt-prefix caching across retain, consolidation, and reflect — default on — to cut token cost and latency.
Cross-Instance Bank Migration
Moving a memory bank from one Hindsight deployment to another — staging to production, self-hosted to Cloud, or between regions — used to mean re-ingesting the source content and paying for every extraction again. 0.8.0 adds first-class migration.
- Whole-bank export/import. The
hindsight-admin export-bankcommand packages a complete bank — memory units, mental models, entities, links, configuration, and mental-model history — into an archive, andimport-bankrestores it into another instance. The destination re-embeds locally against its own embedding model, so no LLM extraction is re-run and the migration is fast and cheap. - Document transfer. A dedicated document-transfer API endpoint moves a bank's source documents between banks without re-running the LLM, so you can rebuild or fork a bank from its originals.
Because the destination re-embeds on import, you can migrate between instances even when they run different embedding back-ends.
Operations & Observability
0.8.0 puts a lot of work into making what Hindsight is doing under the hood visible and easy to operate — from the individual LLM calls behind every request to the long-running jobs that maintain a bank.
LLM Request Tracing
Hindsight makes a lot of LLM calls on your behalf — fact extraction during retain, query analysis and reranking during recall, synthesis during reflect, and consolidation in the background. 0.8.0 records every one of them, per bank, on by default — including failures.
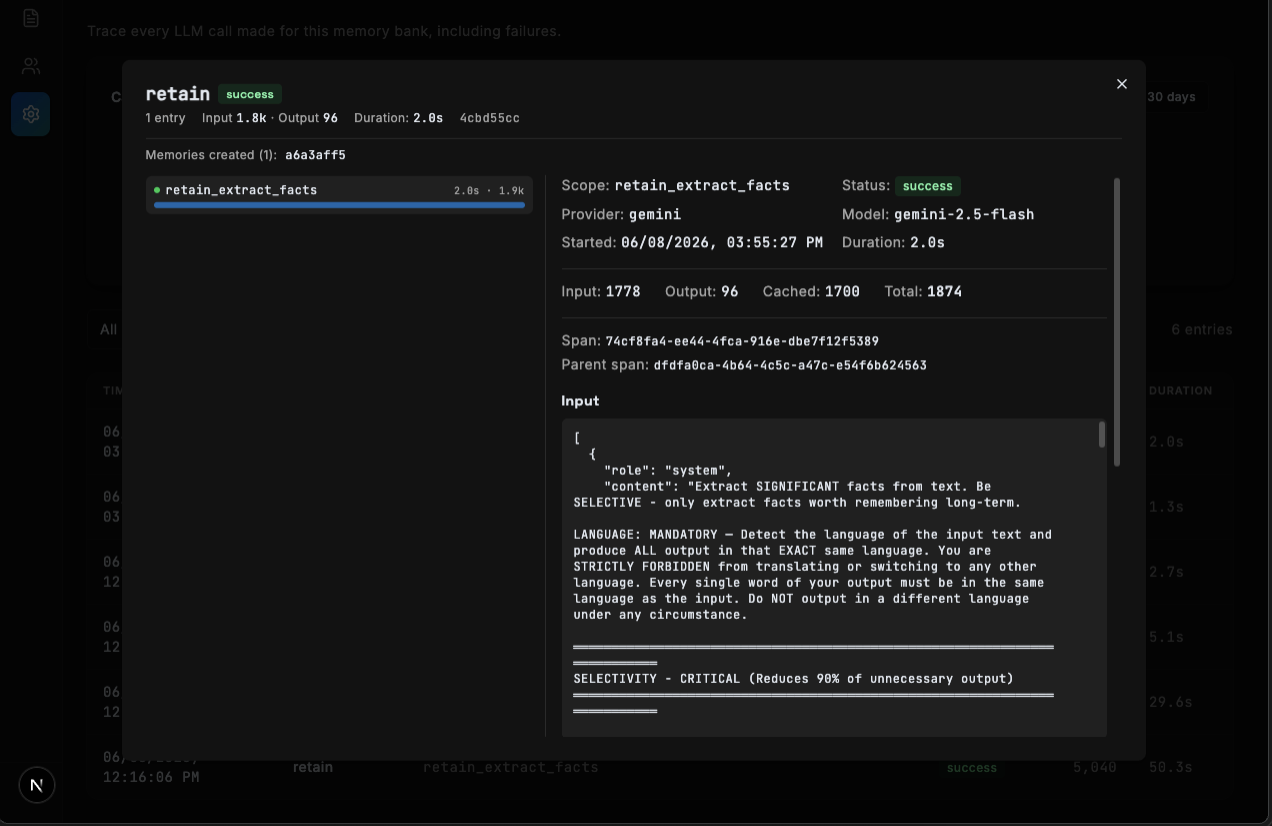
Each trace captures the provider and model, token usage (input, output, cached, total), latency, and the exact prompt and tool calls behind the request. Tracing is recorded through an OpenTelemetry GenAI recorder, with a one-day retention window so traces don't accumulate unbounded. New llm-requests endpoints expose the traces and aggregate statistics, the Control Plane ships the viewer above, and the Python and TypeScript clients now surface the tool_calls and llm_calls trace from reflect so you can see exactly how an answer was produced. Recall traces also preserve the reciprocal-rank-fusion source ranks, so you can tell which retrieval strategy surfaced each result.
If a retain looked wrong or a reflect answer surprised you, you can open the trace and read the actual prompt, model, and tool calls behind it.
Resumable, Inspectable Operations
Long-running work — consolidation and batch retain — now writes a durable progress snapshot as it runs. You can poll an operation to watch it advance, and if a worker restarts mid-run it resumes from where it stopped instead of starting over, so a deploy or a transient crash no longer throws away completed work.
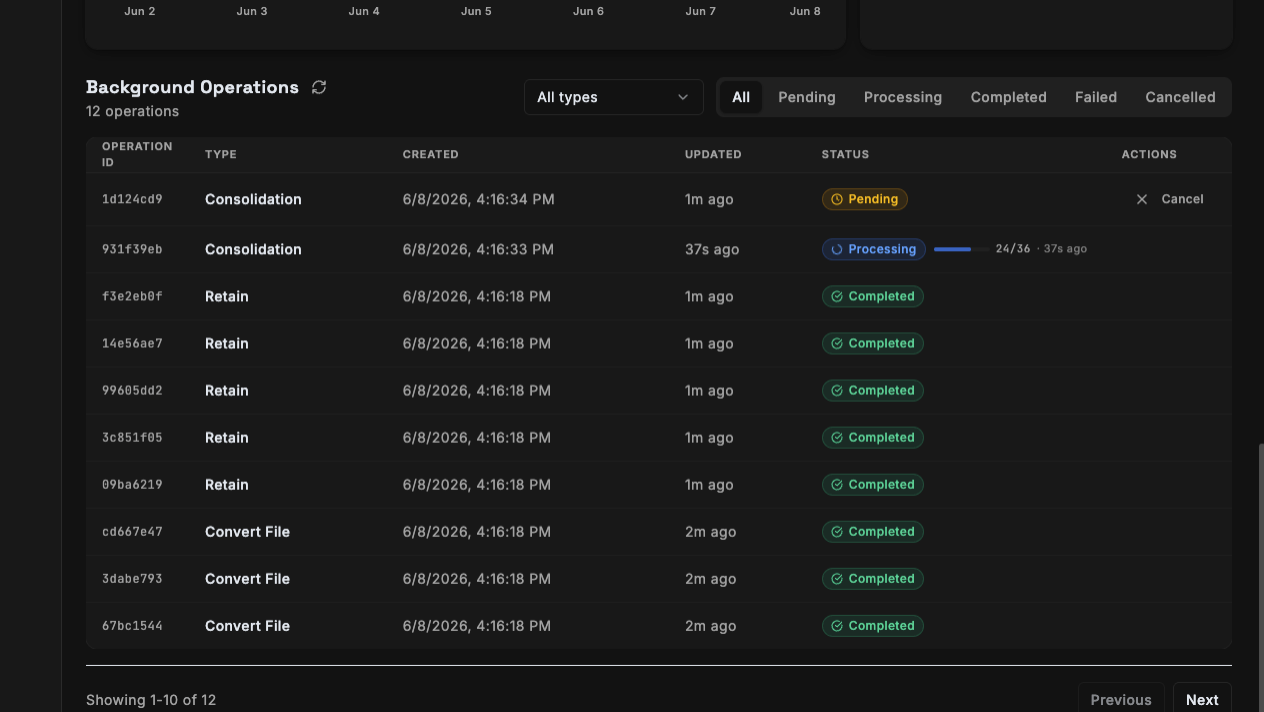
The Control Plane surfaces all of this in a Background Operations view, where you can filter by type or status, watch in-flight progress, and cancel pending work.
Clearer Control Plane
Operation and graph legends are now fully localized, and the audit-log and LLM-request views show a clear "not enabled" splash when a feature is disabled instead of erroring.
Smarter Consolidation
Consolidation — the background process that turns raw facts into a clean set of observations and mental models — is LLM-driven: a model reads new facts and decides whether to update an existing observation or write a new one. In practice the model occasionally drifts, writing a near-identical observation instead of merging into the one already there, and over time those duplicates pile up.
0.8.0 stops leaving this to the model and hardens the infrastructure around it. Built-in de-duplication is now on by default: on both the create and update paths, a new observation within a similarity threshold (default 0.97) of an existing one is detected and merged automatically, instead of being left to accumulate. The drift that used to slip through is now caught deterministically rather than hoped away — a meaningful reliability upgrade for any bank under steady write load.
The effect is large in practice: on our continuous benchmarks, the share of duplicate observations dropped from around 30% to roughly 1% with this release. You can follow the metric live on our continuous performance dashboard.
The de-duplication path is also faster and lighter. The lookup that finds the observation to merge into no longer runs the cross-encoder reranker — consolidation interleaves the retrieval results directly. That drops the reranking pass entirely and is more reliable at surfacing the near-identical twin (the reranker tended to bury it), so consolidation does less work and produces fewer duplicates at the same time.
Provider Prompt Caching
Hindsight now uses provider prompt-prefix caching for the LLM calls behind retain, consolidation, and reflect. The shared, bank-agnostic prefixes of these prompts are cached at the provider, cutting both token cost and latency on repeated calls. It's enabled by default and requires no configuration.
New Integrations
- Claude Agent SDK — a new integration that gives agents built on Anthropic's Claude Agent SDK persistent Hindsight memory.
- Superagent — a safety middleware integration for routing Superagent interactions through Hindsight.
Other Notable Changes
- Faster temporal recall. The temporal entry-point scan is now bounded to the top matches per fact type, fixing a pathological slowdown on banks with many same-dated memories.
- Bounded memory history. Mental-model and observation history moved out of a single JSONB column into dedicated tables, removing an unbounded-growth ceiling that could destabilize large banks.
- More LLM flexibility.
HINDSIGHT_API_LLM_STRICT_SCHEMAis honored across all JSON-schema-capable providers,HINDSIGHT_API_LLM_EXTRA_BODYis applied across all API providers, and the default MiniMax model is upgraded to M3. - ONNX local embeddings. A new ONNX-based local embeddings provider joins the existing local and TEI options.
- Tunable retrieval. Per-strategy retrieval boosts (
semantic,bm25,graph,temporal) and a configurableHINDSIGHT_API_SEMANTIC_MIN_SIMILARITYfloor let you tune recall to your corpus. - External Postgres fixes. VectorChord catalogs are added to the
search_pathso vchord works on externally managed PostgreSQL, and embedding dimensions are validated before pgvector writes to catch mismatches early. - Oracle 23ai backend. Recall and mental-model history now work on the Oracle backend, and document lock/upsert is dialect-aware.
- Robust BM25. PGroonga BM25 query text is escaped so special characters no longer break keyword search.
- More reliable model init. Model initialization fails fast instead of hanging forever when a provider blocks, and
tool_choice="required"is downgraded for servers that silently drop it. - Leaner reflect. A fresh mental model can short-circuit forced retrieval, avoiding an extra LLM call.
- Retain integrity. Retain runs a pre-extraction freshness recheck and serializes concurrent writers to the same document, stops the bank routing key from polluting fact attribution, and surfaces richer per-item outcome metadata.
- Config correctness. Bank configuration
PATCHnow persists for banks that have never been retained to.