How I Built Multi-User AI Memory into a Financial Product from Day One

I'm a co-founder building an AI-powered financial asset management system. Memory was not something I could add later; it had to be part of the design from the beginning.
I started integrating Hindsight last December, before we had real users. Here is what I built and why.
Why I Self-Host
In the financial market, data privacy is a compliance requirement, not a preference. My users' portfolio data, preferences, and conversation history cannot sit on infrastructure I do not control. So I self-host Hindsight using the local deployment path. Same API, same retrieval quality, everything stays in my environment.
The self-hosting path is well-documented and the API is identical, so nothing I describe below is specific to it. If you are not in a regulated industry, Hindsight Cloud is the easier starting point, you get everything I describe here with zero infrastructure to manage.
One Bank, Two Tag Layers
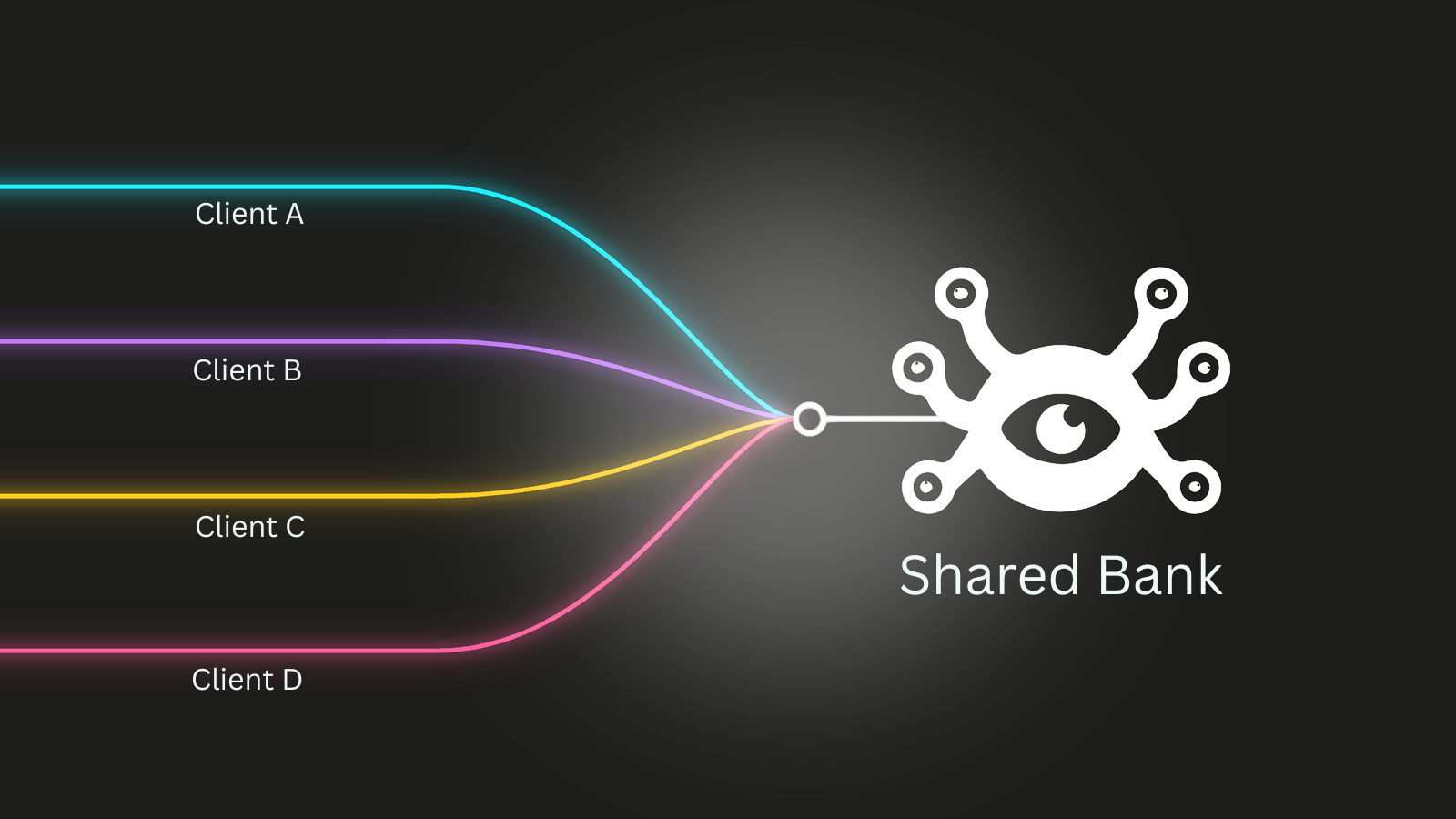
The part of my setup I get the most questions about is how I handle memory for multiple users.
I use a single Hindsight bank. Within that bank, I tag everything by type:
- Company-wide knowledge gets a
sharedtag, things every user's AI should know - Individual user conversations get a
user:<id>tag
When a user asks a question, I recall with tags: ["user:<id>", "shared"] and tagsMatch: "any_strict". That means the AI surfaces both memories that are specific to that user and knowledge that applies to everyone.
The reason I went with one bank instead of one bank per user is that a financial system has two distinct memory needs. There is knowledge that every user should benefit from, how the system behaves, market context, shared decisions we have made as a team. And there is knowledge that should stay private to each individual. Separate banks would mean I could not share the first layer without duplicating it everywhere.
With tags, both layers live in one retrieval space. Adding a new user is as simple as starting to tag their sessions with user:<new-id>. No provisioning, no configuration change.
The Git Hook
One thing I added that has been surprisingly useful: a git hook that scans our codebase and retains knowledge about it with the shared tag.
When a developer pushes code, the hook extracts relevant facts, how key functions work, what patterns we use, architectural decisions that are not obvious from the code alone, and stores them in Hindsight. The next time any developer's AI assistant recalls context, that codebase knowledge surfaces alongside their personal memories.
It means knowledge that would otherwise live only in one person's head, or get buried in a commit message, ends up in a place where everyone's AI can access it.
Integrating from the Start
I made a deliberate decision to wire Hindsight in before we had users, and I think that was the right call.
When you retrofit memory to an AI system, you start with a gap. Everything that happened before the integration is gone. Your early conversations, your first users' preferences, the things the AI learned in the first weeks, none of it is there.
By starting in December, the system has been accumulating context for months. That compounding is real. An AI that has four months of retained knowledge about a user behaves meaningfully differently from one that is starting from scratch.
What I Am Building Next
Two things are on my roadmap.
Document integration. I started with Hindsight's built-in retain file feature but found it too limited for what I need. My plan is to build a more capable ingestion pipeline using Kreuzberg for document parsing. Financial products deal with a lot of documents, filings, reports, disclosures, and getting those into the memory system properly is a different problem from conversation retention.
Structured data. Longer term, I want to explore whether Hindsight can work with structured data from a database. Positions, transactions, prices, these live in databases, not conversations. I do not know yet what the right pattern is, but I am planning to work through it with the Hindsight team.
The Short Version
If you are building a multi-user AI product and thinking about memory, here is what worked for me:
- Self-host when your industry requires it. Otherwise, Cloud is the easier starting point.
- A single bank with tag-based isolation scales better than one bank per user when you have shared context that everyone needs.
- A git hook retaining codebase knowledge as
sharedis a low-effort way to give your whole team's AI assistant shared context. - Start the memory integration early. The value compounds and you cannot recover the gap.
I am still early in exploring what Hindsight can do, I have not touched mental models yet, but the core pattern has been solid since December.