Hindsight Is #1 on BEAM — the Benchmark That Tests Memory at 10 Million Tokens

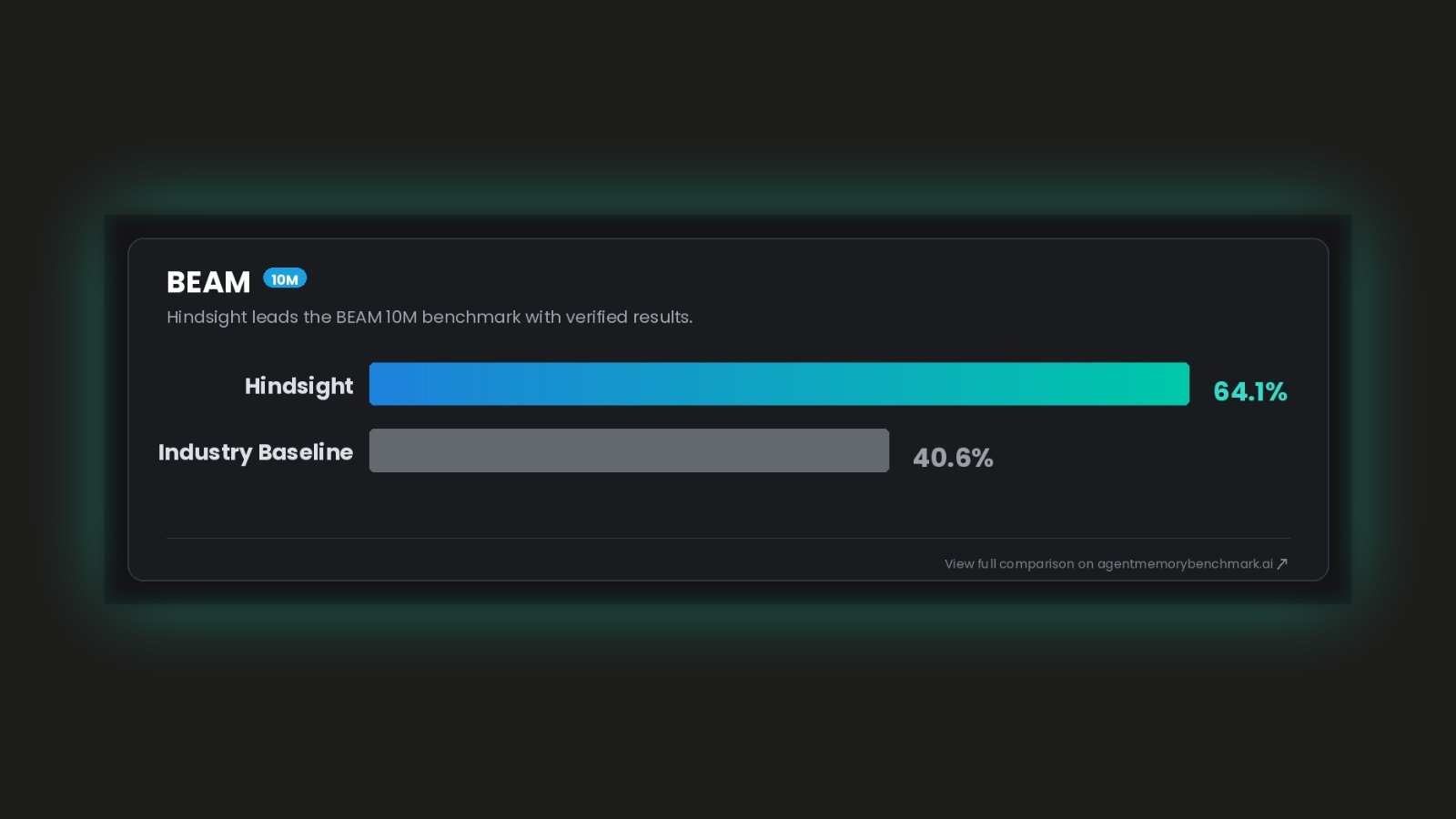
Hindsight is SOTA on BEAM, the benchmark that tests memory at 10 million tokens, where context stuffing is physically impossible and only a real memory architecture survives.
Why the 10M Tier Is the Most Important Result
If you've been following agent memory evaluation, you know LoComo and LongMemEval. They're solid datasets. The problem isn't their quality; it's when they were designed.
Both come from an era of 32K context windows. Back then, you physically couldn't fit a long conversation into a single model call, so needing a memory system to retrieve the right facts selectively was the premise. That made those benchmarks meaningful.
That era is over.
State-of-the-art models now have million-token context windows. On most LoComo and LongMemEval instances today, a naive "dump everything into context" approach scores competitively, not because it's a good architecture, but because the window is large enough to hold the whole dataset. These benchmarks can no longer distinguish a real memory system from a context stuffer. A score on them no longer tells you much.
BEAM ("Beyond a Million Tokens") was designed to fix this. It tests at context lengths where the shortcut breaks down:
| Context length | What it tests |
|---|---|
| 100K tokens | Baseline — most systems handle this |
| 500K tokens | Retrieval starts mattering |
| 1M tokens | Edge of current context windows |
| 10M tokens | No context window is large enough — only a real memory system works |
At 10M tokens, there is no shortcut. You cannot fit the data into context. The only path to a good score is a memory system that can retrieve the right facts from a pool that's too large for any model's attention window. The BEAM paper shows that at this scale, systems with a proper memory architecture achieve over +155% improvement versus the vanilla baseline. That's the regime where the gap between architectures is most pronounced, and where Hindsight's results are most significant.
The Numbers
Here's every published result on the 10M BEAM tier:
| System | 10M score |
|---|---|
| RAG (Llama-4-Maverick) — BEAM paper baseline | 24.9% |
| LIGHT (Llama-4-Maverick) — BEAM paper baseline | 26.6% |
| Honcho | 40.6% |
| Hindsight | 64.1% |
Hindsight scores 64.1% at 10M. The next-best published result is 40.6%. That's a 58% margin. Against the paper baselines, it's more than 2.4x.
The full picture across all BEAM tiers:
| Tier | Hindsight | Honcho | LIGHT baseline | RAG baseline |
|---|---|---|---|---|
| 100K | 73.4% | 63.0% | 35.8% | 32.3% |
| 500K | 71.1% | 64.9% | 35.9% | 33.0% |
| 1M | 73.9% | 63.1% | 33.6% | 30.7% |
| 10M | 64.1% | 40.6% | 26.6% | 24.9% |
One detail worth noting: Hindsight's 1M score (73.9%) is higher than its 500K score (71.1%). Performance doesn't degrade as token volume increases; it improves. Most systems show the opposite. That's the architecture working as intended, and it's where the gap versus other approaches becomes most visible.
Results are tracked publicly on Agent Memory Benchmark. For background on why we built the benchmark and how it's evaluated, see Agent Memory Benchmark: A Manifesto.
What 10 Million Tokens Actually Looks Like
To make the scale concrete: 10 million tokens is roughly a year of daily conversations with an AI agent, a company's entire internal documentation corpus, or the complete output of a software project across hundreds of sessions. It's not a synthetic stress test; it's the real volume that production systems accumulate over time.
At that scale, context stuffing stops being a tradeoff and starts being physically impossible. GPT-4o's 128K context window holds about 1.3% of a 10M-token history. Gemini 1.5 Pro's 2M window holds 20%. Even the largest context windows available today top out well below what you'd need. An agent operating at that volume has no choice but to retrieve selectively, and the quality of that retrieval is what separates functional memory from broken memory.
And even setting the size limit aside, stuffing context doesn't actually work well. Chroma's research on context rot shows that LLM performance degrades significantly as input length increases, even within a model's supported window. At 128K tokens, models are already losing coherence and missing information buried in the middle. A 1M-token context window doesn't give you 1M tokens of reliable attention; it gives you diminishing returns most of the way there. Selective retrieval isn't just necessary at 10M tokens — it's better even at scales where stuffing is technically possible.
This is why we invested in the architecture choices that drove these BEAM results: a rebuilt retrieval pipeline, improved fact extraction, and observations, a process that synthesizes higher-order knowledge from accumulated facts so that retrieval returns insights, not just raw history. Those choices compound at scale. They're also what we describe in more detail in our Agent Memory Benchmark manifesto, if you want the reasoning behind how we evaluate and what we're optimizing for.
Free and Local — or Cloud
Hindsight runs fully locally. No account, no API key, no data leaving your machine:
# Start the local daemon — no install required
uvx hindsight-embed
Your agent connects to http://localhost:8888. Full setup in the quick start.
For memory that follows you across machines, or that multiple agents can share, connect to Hindsight Cloud instead. One config change:
{
"hindsightApiUrl": "https://api.hindsight.vectorize.io",
"hindsightApiToken": "hsk_your_token"
}
Both modes use the same API. Switching from local to cloud is a config change, not a migration.
Get Started
- GitHub: github.com/vectorize-io/hindsight
- Quick start: hindsight.vectorize.io/developer/api/quickstart
- Cloud: ui.hindsight.vectorize.io/signup
- BEAM paper: arxiv.org/pdf/2510.27246
- Full leaderboard: agentmemorybenchmark.ai/dataset/beam
- AMB manifesto: Why we built Agent Memory Benchmark
- Integration guides: Codex · Hermes · Claude Code