What's new in Hindsight 0.4.13 and 0.4.14

Hindsight 0.4.13 and 0.4.14 add Chat SDK support, CrewAI integration, configurable MCP tools, graph retrieval tag filtering, and a new reranker provider—plus a set of reliability and performance improvements across the board.
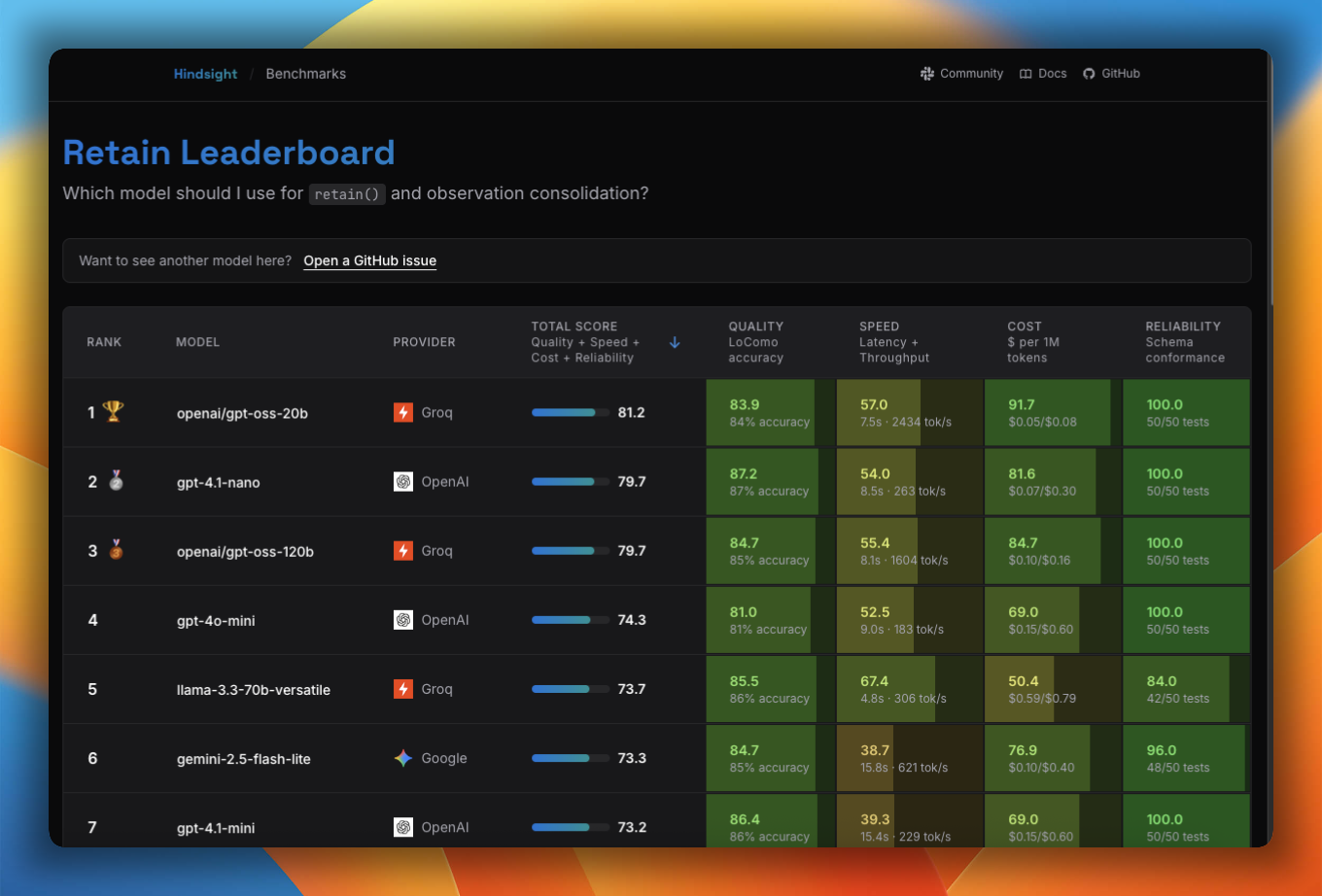
- Model Leaderboard: See how every supported LLM ranks for retain and reflect across accuracy, speed, and cost.
- Chat SDK Integration: Give chatbots persistent memory with a single SDK.
- CrewAI Integration: Add long-term memory to CrewAI agents.
- Configurable MCP Tools: Choose which MCP tools are exposed per memory bank.
- Batch Observations Consolidation: Process multiple observations more efficiently in a single pass.
- ZeroEntropy Reranker: New reranker provider option for improved recall quality.
- Observation Source Facts: Recalled observations now include the underlying facts they were derived from.
Model Leaderboard
We launched a public Model Leaderboard that ranks every supported LLM on both the retain and reflect operations—measuring fact extraction quality, speed, and cost side by side. Whether you're optimizing for accuracy or trying to cut inference costs, the leaderboard gives you real data to pick the right model for your workload.
Chat SDK Integration
Hindsight now integrates with the AI SDK useChat hook, making it straightforward to give any chatbot persistent memory across sessions.
import { useChat } from "ai/react";
import { createHindsightMiddleware } from "hindsight-sdk/chat";
const { messages, input, handleSubmit } = useChat({
middleware: createHindsightMiddleware({
bankId: "user-123",
serverUrl: "http://localhost:8888",
}),
});
The middleware transparently retains conversation turns and injects recalled context into each request—no changes needed to your existing chat route or LLM calls.
See the Chat SDK documentation for configuration options and a full quickstart.
CrewAI Integration
CrewAI agents can now use Hindsight as a persistent memory backend. The integration plugs into CrewAI's memory interface and routes storage and retrieval through a Hindsight bank.
from crewai import Agent, Crew
from hindsight_integrations.crewai import HindsightMemory
crew = Crew(
agents=[...],
tasks=[...],
memory=True,
memory_config={
"provider": "hindsight",
"config": {
"bank_id": "my-crew",
"server_url": "http://localhost:8888",
},
},
)
This gives CrewAI agents access to the full Hindsight retrieval stack—semantic search, BM25, graph traversal, and reranking—rather than the default in-process storage.
See the CrewAI integration documentation for details.
Configurable MCP Tools
You can now configure which MCP tools are exposed for each memory bank. Previously, all tools were always available; now you can restrict the tool set to match exactly what an agent or user should be able to do.
export HINDSIGHT_API_MCP_ENABLED_TOOLS="recall,retain"
This release also expands the MCP tool set with additional tools and new parameters on existing tools, giving MCP clients more control over memory operations without needing a custom API integration.
Batch Observations Consolidation
Observation consolidation now processes multiple observations in a single batched pass instead of individually. This reduces LLM call overhead when a retain operation triggers consolidation across several entities. In our testing, this resulted in a 10x speed improvement for consolidation-heavy workloads.
No configuration is required—the improvement applies automatically when observations are consolidated after ingestion.
ZeroEntropy Reranker
ZeroEntropy is now available as a reranker provider. It joins the existing options (local cross-encoder, TEI) for reranking recalled results.
export HINDSIGHT_API_RERANKER_PROVIDER=zeroentropy
export HINDSIGHT_API_ZEROENTROPY_API_KEY=your-key
Observation Source Facts
When recalling observations, the response now includes the source facts that the observation was derived from. This makes it easier to trace why an observation was formed and to verify its provenance.
results = client.recall(bank_id="my-bank", query="user preferences")
for result in results:
if result.type == "observation":
print(result.text)
for fact in result.source_facts:
print(" -", fact.text)
Other Updates
0.4.14
- Bank configuration API enabled by default: The per-bank config API is now on by default; set
HINDSIGHT_API_ENABLE_BANK_CONFIG_API=falseto disable it. - OpenClaw: Added options to toggle
autoRecalland exclude specific LLM providers. Fixed health checks to correctly pass the auth token. - Reflect and retain customization: Increased configuration options for reflect, retain, and consolidation behavior.
- Source document metadata: Fact extraction results now include source document metadata.
- Embedding dimension validation: A clear error is raised when embedding dimensions exceed pgvector HNSW limits, instead of failing at runtime.
- Multi-tenant schema isolation: Fixed isolation issues in storage and the bank config API.
- Recall performance: Reduced memory usage during retrieval.
0.4.13
- Default OpenAI model: Switched to
gpt-4o-minias the default OpenAI LLM, reducing costs for new deployments. - MCP compatibility: Aligned the local MCP implementation with the server spec and removed the deprecated
statelessparameter. - Docker named volumes: Fixed startup failures when using named Docker volumes.
- Reranker stability: Prevented crashes when an upstream reranker provider returns an error.
- Temporal ordering: Improved accuracy of fact temporal ordering by reducing per-fact time offsets.
- Document tracking: Fixed documents not being tracked when fact extraction returns zero facts.
Feedback and Community
Hindsight 0.4.13 and 0.4.14 are drop-in replacements for 0.4.x with no breaking changes.
Share your feedback:
For detailed changes, see the full changelog.