How We Solved Memory Conflicts in Hindsight

One of the hardest problems we tackled in Hindsight was dealing with contradictions. When you're building a memory system for AI agents, reality isn't static. It evolves.
A CRM agent might learn that "Acme Corp is a key prospect" in January, then encounter "Acme Corp is now a paying customer" in March. Naive approaches either lose the history or drown in duplicate facts.
We needed a system that could handle this gracefully. Here's how we built it.
The Core Problem: Facts vs. Knowledge
Early on, we made a distinction that shaped the way we store and receive memories: raw facts aren't the same as consolidated knowledge. Facts are immediate observations; what an agent learns in a single interaction. Knowledge is durable understanding extracted from those facts over time.
Our consolidation pipeline runs as a background job after new memories are retained, transforming ephemeral facts into lasting knowledge. The key insight is that we don't just store the latest information, we track how knowledge evolves.
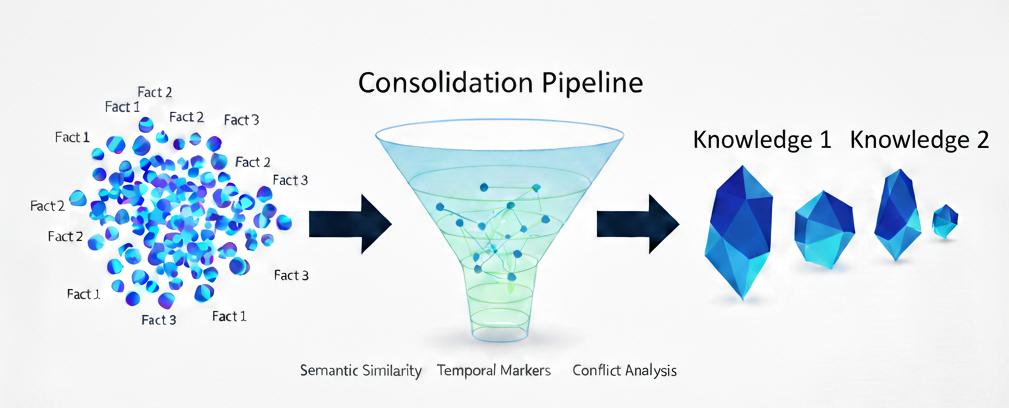
Finding Related Information
When a new fact comes in, we first need to find existing observations that might conflict with it. This happens in our _find_related_observations function, which uses the full recall system with:
- Semantic similarity via embeddings to surface conceptually related observations
- Token budget that naturally limits comparison scope via
consolidation_max_tokens - Security-aware filtering using strict tag matching to prevent cross-user information leakage
recall_result = await memory_engine.recall_async(
bank_id=bank_id,
query=query,
max_tokens=config.consolidation_max_tokens,
fact_type=["observation"],
tags=tags,
tags_match="all_strict",
)
LLM-Powered Conflict Analysis
The real work happens in _consolidate_with_llm, where a single LLM call analyzes the new fact against existing observations. We provide rich context: the text of existing observations, their proof counts (how many supporting facts), and source memories. We organize those memories into a time series with dates and order them chronologically.
This lets the model make informed decisions about whether new information is redundant, contradictory, or represents a genuine state change.
Three Merge Strategies
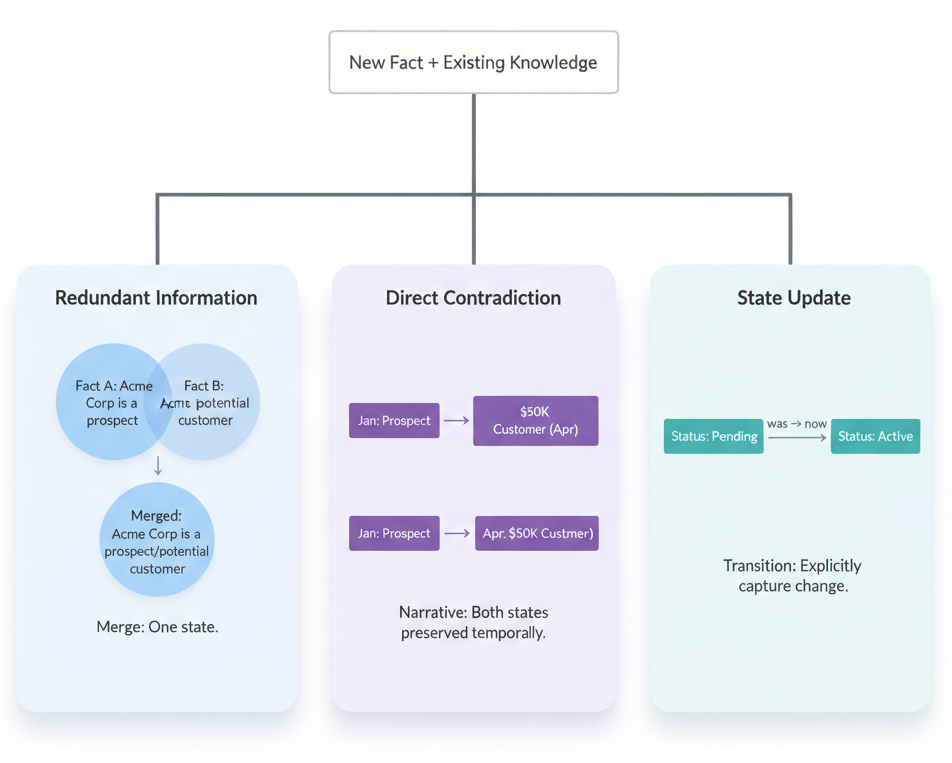
Our consolidation prompt defines three core merge rules:
Redundant information: When the same information is worded differently, we update the existing observation. "Acme Corp is a prospect" plus "Acme Corp is a potential customer" just becomes a single, cleaner observation.
Direct contradictions: When opposite information exists about the same topic, we preserve both states with temporal markers. The critical rule: updated text must capture both states. We don't overwrite old information. Instead, we try to create a temporal narrative that explains how the facts change over time. When no clear explanation exists, we consider the most recent data point to be up-to-date.
State updates: When new information replaces old state, we explicitly capture the transition with phrases like "used to," "now," or "changed from X to Y." We never just state the new fact, we capture the evolution.
Preserving Business Relationship History
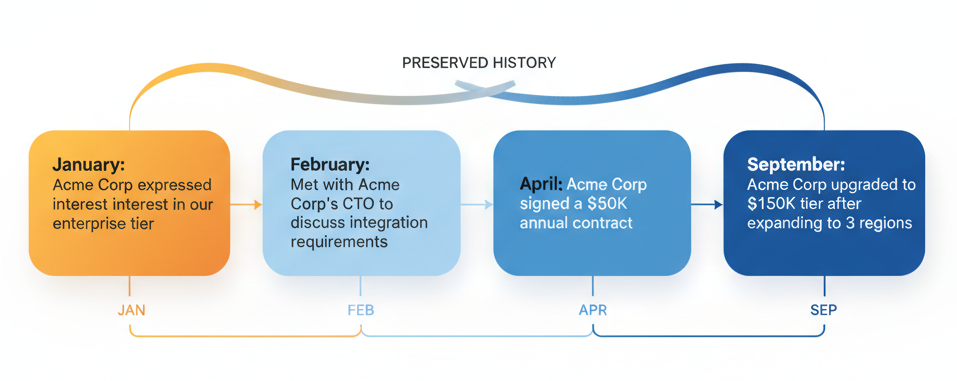
Consider how this handles an evolving business relationship. An agent learns these facts over six months:
- January: "Acme Corp expressed interest in our enterprise tier"
- February: "Met with Acme Corp's CTO to discuss integration requirements"
- April: "Acme Corp signed a $50K annual contract"
- September: "Acme Corp upgraded to the $150K tier after expanding to 3 regions"
A naive system might just keep the latest fact: "Acme Corp is on a $150K contract." Useful, but you've lost the relationship arc.
Our system consolidates this into something like: "Acme Corp progressed from prospect (January) to $50K customer (April), then upgraded to $150K tier in September after regional expansion."
The full journey is preserved. An agent can answer "How did we land Acme Corp?" without losing the relationship history that makes that question meaningful.
Temporal Metadata
We maintain temporal metadata for each observation:
occurred_start = LEAST(occurred_start, COALESCE($7, occurred_start))
occurred_end = GREATEST(occurred_end, COALESCE($8, occurred_end))
mentioned_at = GREATEST(mentioned_at, COALESCE($9, mentioned_at))
This ensures occurred_start keeps the earliest time something was true, occurred_end tracks the most recent observation, and mentioned_at records when it was last referenced.
History as an Audit Trail
Every observation maintains a complete change history:
history.append({
"previous_text": model["text"],
"changed_at": datetime.now(timezone.utc).isoformat(),
"reason": reason,
"source_memory_id": str(memory_id),
})
This audit trail lets the system explain how knowledge evolved, trace back to source facts that caused updates, and provide reasoning for why information changed. When an agent says "Acme Corp is a $150K customer," it can also explain how it knows that and what changed along the way.
Security at the Boundary
One design decision we're particularly happy with: tag-based security boundaries during consolidation.
New observations inherit their source fact's tags. When updating existing observations, tags merge (union) so all contributors can see the knowledge they helped create. Consolidation only happens within the same security scope. Strict matching prevents information leakage while still allowing collaborative knowledge building.
existing_tags = set(model.get("tags", []) or [])
source_tags = set(source_fact_tags or [])
merged_tags = list(existing_tags | source_tags)
Durable Knowledge, Not Ephemeral State
A principle that significantly reduced false conflicts: we distinguish between durable knowledge and ephemeral state.
Good consolidation extracts lasting facts. "User visited Acme Corp at Room 105" becomes "Acme Corp is located in Room 105." But "User is currently in Room 105" isn't tracked because ephemeral position data changes constantly.
This focus on durability means the system isn't constantly flagging temporary state changes as conflicts.
Why This Matters
Handling contradictory information in agent memory doesn't require picking winners and losers. By tracking temporal evolution, preserving history, and consolidating intelligently, we built a system that maintains nuanced understanding of how knowledge changes.
For agents that need to track changing preferences, understand temporal relationships, maintain audit trails, and build trust through explainable updates.
This approach allows Hindsight to provide more than just memory storage. It can provide context that improves with every interaction.